
The Squash-vs-Granular Trap: How a 105-File Merge Conflict Resolved Into 12,118 Lines of Clean History
A long-lived integration branch went unmergeable two months after the trunk took its first big slice as a squash merge. Plain git merge spat 105 conflicted files. This post walks the playbook that landed it: how to spot the trap, how to categorize the conflicts, the exact commands that resolved 94 of them mechanically, and the three subtleties that bite you when you reach for `git checkout --ours`.
GitHub showed PR #22 in red: CONFLICTING, 105 files. I had expected a clean merge. The branch was siem-loglake, where I had spent two months stacking the SIEM log-lake cutover and two more phases of work on top of it. What I had forgotten was that the trunk took that same cutover two months earlier as a single squash commit, then kept moving. By the time I opened PR #22 (siem-loglake -> main), the branch sat 174 commits ahead of an ancestor that predated everything I cared about, and plain git merge could not reconcile the two. It was right not to try.
Landing it did not take a rebase of 174 commits or a hand-merge of all 105 files. It took a categorization pass, four lines of bash that cleared 94 of the conflicts in one loop, and about an hour of reading the other 11 carefully. The result on main: 85 files changed, +12,118 / -32, almost entirely additive, CI green, all 174 granular commits preserved as parents of one merge commit. Here is how it went, in order.
The Setup: Two Months, Two Histories#
Two months earlier, PR #16 landed the SIEM log-lake cutover on main as a squash merge. One commit. SHA 14a0661. 224 files, +35,469 / -7,267. That commit is the only thing on main that describes the cutover.
The integration branch, siem-loglake, still carried the same cutover as 161 individual commits, each TDD-shaped, each with its own message. I kept building on siem-loglake because the work was not done: the gmail-phishing integration shipped next, then the LOG LAKE dashboard panel and a stack of operator fixes. By the time PR #22 (siem-loglake -> main) opened, the branch was 174 commits ahead of an ancestor (a965def) that long predated the squash.
The two histories had diverged from the same pre-cutover base and never reconverged. main carried the cutover as one commit. siem-loglake carried it as 161 commits plus 13 more on top. Git could not see those two descriptions as the same content because, in the only language git speaks (commit ancestry), they are not.
What's a squash merge?
A squash merge takes every commit on a feature branch and collapses them into a single commit on the target branch. The target's history stays linear, but the feature branch's per-commit lineage is destroyed. Git no longer has any way to recognize that the squash commit's content already exists somewhere else in the graph.
Why a Squash Merge Made It Unmergeable#
The problem in one diagram:
a965def (pre-cutover base, last shared ancestor)
/ \
/ \
v v
main: [14a0661 (squash cutover)] --> [6c13af6] --> [9322e4c] --> ...
(DNS panel) (TTL fix)
siem-loglake: [c0...] --> [c1...] --> [c2...] --> ... --> [c160...] --> ... --> [c173...]
<-------- 161 granular cutover commits --------> <- gmail + LOG LAKE ->
When you ask git to merge siem-loglake into main, it picks the merge base (the most recent common ancestor) and three-way-merges from there. The most recent common ancestor of main and siem-loglake is a965def, the pre-cutover base. Everything that happened on either branch after that point is a "change" relative to the base.
The trap is that every file the cutover touched on either branch shows as "changed on both sides" relative to the merge base, because both sides changed it independently. Git has no way to say "actually these two changes describe the same final state." The squash commit and the 161 granular commits are not ancestors of each other. They are siblings descended from the same parent, both carrying overlapping but independently-written content.
The trunk's own additions on top of the squash (the DNS search panel in 6c13af6, the TTL test fix 9322e4c, the post-merge CI cleanup in 1bd4997 and ba6ce37) layered on more divergence. By the time PR #22 opened, every cutover-touched file conflicted, regardless of whether the content was actually different.
The trap, in one line
A squash merge is one-way: it lets the trunk go forward, but it leaves any long-lived branch still holding the un-squashed version permanently re-conflicting with itself.
This is the underlying mechanic behind a lot of "why won't this branch merge?" pain. If the integration branch is short-lived, you rebase, force-push, and move on. If the integration branch has months of work on top of the squashed slice, rebasing is not a small operation: every commit on top has to replay against the squash commit's tree, and the per-commit conflicts can be worse than the merge-commit conflicts.
The real fix is to categorize the merge-commit conflicts and resolve them in bulk. That is what this post is about.
The Categorization Step#
Not all 105 conflicts are equal. Most of them are conflicts in name only. The squash commit's content and the integration branch's content describe the same files, and the integration branch has the more evolved version because it kept getting touched. So taking the integration branch's version is correct for the vast majority of files.
One command splits the real conflicts from the fake ones:
git diff --name-only 14a0661 origin/main
That gives you the list of files with genuinely-new-on-main content since the squash commit landed. In my case, that list was tiny:
backend/src/homenet_dashboard/clickhouse/queries.py(new DNS search helpers)backend/src/homenet_dashboard/routers/dns.py(new/api/dns/searchendpoint)backend/tests/clickhouse/test_queries.py(tests for the DNS helpers)backend/tests/test_migration_0006.py(the TTL test fix from9322e4c)frontend/src/components/HealthStrip.tsx(DNS search indicator)frontend/src/pages/DnsPage.tsx(the search panel UI)frontend/src/queryKeys/query-keys.ts(newdnsSearchkey)frontend/src/api/types.ts(new types)frontend/src/pages/DnsPage.test.tsx(panel tests)frontend/src/test/msw-handlers.ts(mock handler for the new endpoint)
Ten files. Out of 105. Everything else is pure cutover that the squash commit also touched and that the integration branch's evolved version is the truth for.
The 105 split cleanly:
| Group | Count | Resolution |
|---|---|---|
| Pure cutover / CI-reformat-only | 94 | git checkout --ours (integration branch's evolved version) |
queries.py (bidirectional) | 1 | base on --ours, splice in main's added block |
routers/dns.py, test_queries.py, test_migration_0006.py, HealthStrip.tsx, DnsPage.tsx | 5 | main's verified superset versions |
msw-handlers.ts | 1 | --ours (had unique gmail + SIEM mock handlers) |
query-keys.ts, types.ts, DnsPage.test.tsx | 3 | edit in place (small / blank-line conflicts) |
The 94 in the first row are the easy ones. Every one of them is a file the squash commit touched as part of the cutover, that the integration branch then evolved further. Taking the integration branch's version preserves the evolution and overwrites the now-stale squash version of the same content.
The next four rows are the careful set. Each one needs a per-file decision.
The categorization commands
Three commands give you the categorization in under thirty seconds:
git diff --name-only <squash-commit> origin/main > /tmp/new_on_main.txt
git diff --name-only --diff-filter=U > /tmp/all_conflicts.txt
comm -23 <(sort /tmp/all_conflicts.txt) <(sort /tmp/careful_set.txt) > /tmp/group1.txt
The first is "what genuinely changed on main since the squash." The second is "what is currently conflicted." The third is "everything in the conflict list that is not in the careful set." That last list is Group 1.
The Walkthrough With Exact Commands#
Here is the resolution from start to finish. The first step is to do all of this on a throwaway branch so the original integration branch and trunk stay intact until you are ready to land.
# 1. Throwaway reconcile branch off the granular tip.
git checkout -b reconcile/loglake-to-main origin/siem-loglake
# 2. Merge main IN (so main becomes an ancestor for later fast-forward).
git merge --no-commit --no-ff origin/main # stops at conflicts
Step 2 starts a merge but does not commit it. The working tree is now full of conflict markers; the index records both sides for every conflicted file. This is the state where the categorization happens.
# 3. Identify "genuinely-new-on-main" files.
git diff --name-only 14a0661 origin/main > /tmp/new_on_main.txt
git diff --name-only --diff-filter=U > /tmp/all_conflicts.txt
# Group 1 = all conflicts MINUS the careful set.
# The "careful set" is built by inspecting /tmp/new_on_main.txt
# and naming the files where main has unique content worth keeping.
cat > /tmp/careful_set.txt <<'EOF'
backend/src/homenet_dashboard/clickhouse/queries.py
backend/src/homenet_dashboard/routers/dns.py
backend/tests/clickhouse/test_queries.py
backend/tests/test_migration_0006.py
frontend/src/components/HealthStrip.tsx
frontend/src/pages/DnsPage.tsx
frontend/src/queryKeys/query-keys.ts
frontend/src/api/types.ts
frontend/src/pages/DnsPage.test.tsx
frontend/src/test/msw-handlers.ts
EOF
comm -23 <(sort /tmp/all_conflicts.txt) <(sort /tmp/careful_set.txt) > /tmp/group1.txt
/tmp/group1.txt is now the 94-file list. Resolving them takes one line:
# 4. Mechanical resolution for Group 1.
while read f; do
git checkout --ours -- "$f" && git add -- "$f"
done < /tmp/group1.txt
--ours here means "the side I started on," which is siem-loglake. The convention is counterintuitive during a merge: when you ran git merge origin/main from reconcile/loglake-to-main, --ours is the reconcile branch (your starting side) and --theirs is main (the side you are merging in). I get this wrong half the time. The rule that works: --ours is whoever's tip your HEAD was at when you started the merge.
After step 4, those 94 files are resolved. The remaining work is the careful set.
# 5a. Five files where main's version is the verified superset.
for f in \
backend/src/homenet_dashboard/routers/dns.py \
backend/tests/clickhouse/test_queries.py \
backend/tests/test_migration_0006.py \
frontend/src/components/HealthStrip.tsx \
frontend/src/pages/DnsPage.tsx; do
git checkout --theirs -- "$f" && git add -- "$f"
done
Each of these had to be eyeballed first. routers/dns.py: the integration branch had no DNS search endpoint, so main's version is strictly a superset. test_queries.py: same shape. test_migration_0006.py: contained the TTL fix from 9322e4c and nothing on the integration branch had touched the test. HealthStrip.tsx and DnsPage.tsx: integration branch had no DNS search panel work, so main's version is strictly more functional.
The verification pattern is the same in every case: git diff :2:<file> :3:<file> (which shows ours vs theirs for a conflicted path) makes the difference obvious. If theirs is a clean superset of ours, --theirs is safe. If it is not a superset, you have to merge by hand.
The one file that needed bidirectional splicing was queries.py. The integration branch had a collector_health argMax bug fix and the SIEM ingestion-strip helpers that main does not have. Main had three new DNS-search query helpers (dns_search, dns_search_top_clients, dns_search_sparkline) that the integration branch does not have. Both halves need to land in the final file.
# 5b. queries.py: take --ours as the base, splice in main's added block.
F=backend/src/homenet_dashboard/clickhouse/queries.py
git checkout --ours -- "$F"
# Extract the genuinely-new block from main's version (stage 3 = theirs).
git show :3:"$F" | sed -n '482,652p' > /tmp/block.txt
# Insert at a known anchor (just before client_network_history).
awk '
/^def client_network_history\(/ && !done {
while ((getline line < "/tmp/block.txt") > 0) print line
print ""; print ""
done = 1
}
{ print }
' "$F" > "$F.merged" && mv "$F.merged" "$F"
# Verify the splice parses and both contributions are present.
python -m py_compile "$F"
grep -n 'def dns_search' "$F"
grep -n 'argMax' "$F"
git add "$F"
The line numbers for the splice (482 to 652) came from a one-time read of main's version with a known section delimiter. sed -n is the right tool for "extract this contiguous block from a known good source." awk is the right tool for "insert at this anchor pattern." git show :3:<file> reads the conflicted theirs-side from the index without touching the working tree.
The verification step matters. py_compile confirms the splice did not leave a syntax error or a dangling block. grep -n 'def dns_search' confirms main's contribution is present. grep -n 'argMax' confirms the integration branch's contribution survived.
The last three files, the in-place edits, needed a different approach.
# 6. Commit the content-resolution merge.
git commit -m "Merge origin/main into siem-loglake (reconcile squash-vs-granular cutover)"
That commit becomes 3264e63. The reconcile branch's HEAD now contains the content of both histories, no conflict markers, and the merge graph records both parents.
If you'd rather read this as slides, the deck version is here: Squash-vs-Granular Reconcile Playbook slide deck (PDF). Same arc as the post, fewer words per page.
The Skipped Cleanup: How It Surfaced#
The merge commit's content was correct. The merge commit's formatting was not. Running make lint immediately surfaced 250 ruff errors, 89 reformats, and 22 prettier files.
The cause: when 1bd4997 and ba6ce37 landed on main as the post-cutover lint cleanup, they applied ruff --fix and ruff format to the trunk's cutover-touched files. The integration branch never received that cleanup. When I took --ours on Group 1 (94 files), I pulled the pre-cleanup formatting along with the evolved content.
Taking --ours on a file the trunk has reformatted pulls the unreformatted version along with the content. The reformatting is real content from the trunk's side, but to the merge tool it is the wrong version of identical content, and --ours discards it.
The diagnostic is short. If main's tip (which passed CI) passes make format-check locally, then your local ruff is at parity with CI and reformatting is safe.
git checkout origin/main -- .
make format-check # should pass; this confirms local-vs-CI parity
git checkout HEAD -- .
If main fails locally, your local ruff is newer than CI's and reformatting would introduce divergence from CI's expectations. Stop. Pin the ruff version, re-test.
When parity is confirmed, reproduce the cleanup as a separate commit on top of the merge:
make format
make lint
git add -u
git commit -m "style: reproduce main's ruff + prettier cleanup on merged content"
That becomes 2a841b1. It mirrors how main got its own 1bd4997 and ba6ce37, and it stays easy to revert and inspect.
Why a separate commit and not a merge-commit amendment
Folding the cleanup into the merge commit conflates two different changes: "merged content from main" and "ran the formatter." Keeping them separate makes the merge commit's diff readable (it shows the content reconciliation only) and the cleanup commit's diff readable (it shows the formatter's footprint only). When you come back to this in six months, the separation is what keeps each diff readable and each commit revertible on its own.
The zip(strict=True) Autofix Trap#
ruff check --fix autofixed B905 zip without explicit strict= to strict=True at every call site. Backend ruff went green. One test then failed: test_writer_called_with_merged_findings.
The test deliberately passes mismatched-length lists. It relies on the original plain-zip truncation behavior, where zipping an N-element list with an N+1-element list yields N pairs and silently drops the extra. strict=True turns that silent truncation into a ValueError.
B905's docs make this sound like a safety improvement. In one sense, it is: silent truncation is a footgun. In another sense, it is a behavior change at every call site where the implicit contract is "zip to the shortest." If the call site is already correct under that contract, the autofix breaks it.
The fix has to read the call sites and decide per site. In my code, two production call sites (finding_transformer.transform_all_signals and poll.poll_security_signals) zip a fixed registry list against a possibly-shorter results list, where the truncation is the existing tolerant contract. Those got strict=False (explicit acknowledgement of the contract). Test sites that assert equal length immediately before zipping got strict=True. Every change is one line:
# Before (autofixed, breaks the contract):
for signal_id, result in zip(SIGNAL_REGISTRY, results, strict=True):
# After (explicit, preserves the contract):
for signal_id, result in zip(SIGNAL_REGISTRY, results, strict=False):
Read the tests before accepting a B905 autofix
strict=True is a behavior change at any call site where the implicit contract is "zip-to-shortest." Before letting ruff land the autofix, grep for the test names that exercise the call site and read them. If the test asserts shape equality before the zip, strict=True is safe. If the test exercises mismatched-length inputs, strict=False is the correct answer.
Editing in Place vs git checkout --ours/--theirs#
This is the subtlety that bit me twice during the careful set and that nobody warns you about clearly enough.
git checkout --ours <file> takes the whole ours version, including any auto-merged regions. It also drops any auto-merged content from theirs.
That last part is the trap. Git's three-way merge auto-resolves regions where only one side changed. If main added a new export at the top of a file and the integration branch added a new export at the bottom, the merge auto-resolves both regions and only flags the third region where both sides changed the same line. Run git checkout --ours on that file and you silently drop main's auto-merged export.
I hit this on query-keys.ts. The conflict was a tiny block of new siemQuery keys near the bottom. Main had added a dnsSearch query key elsewhere in the same file as part of the DNS search panel. The conflict region was both sides' edits to the SIEM section. Main's dnsSearch addition was auto-merged in a different region. --ours would have taken the SIEM section (correct) and dropped dnsSearch (wrong).
The rule that works:
`--ours` and `--theirs` are file-level operations, not region-level operations
For any file where one side has content in the auto-merged regions that you must keep, edit the conflict markers in place. Do not use --ours or --theirs. The simplest pattern: open the file, find each <<<<<<< marker, pick the correct lines, delete the markers and the wrong-side lines, save, git add.
For query-keys.ts, types.ts, and DnsPage.test.tsx, the resolution was a manual edit in the conflicted region: pick the lines that needed to be present from both sides, delete the markers, save. The auto-merged regions in those files were preserved automatically because I never told git to take a whole side.
How do you know in advance which files need in-place edits? Two signals:
- The file is in the careful set (you already know main has unique content somewhere in it).
git diff --diff-filter=A :1:<file> :2:<file> :3:<file>shows more than one hunk per side, or the conflicted hunks are short relative to the rest of the file.
The defensive default is: if a file is in the careful set, do not run --ours or --theirs on it without first checking that the whole file's content matches your intent. Run git diff :2:<file> :3:<file> and read the diff before committing.
Landing the Result#
With the merge commit and cleanup commit in place, the reconcile branch was ready. The rest is procedure:
# Push the reconcile branch.
git push -u origin reconcile/loglake-to-main
# Open the fresh PR.
gh pr create --base main --head reconcile/loglake-to-main \
--title "Reconcile siem-loglake into main" \
--body "Resolves the squash-vs-granular trap from PR #22. See merge commit for resolution notes."
That became PR #23. CI ran independently of the original conflicted PR: backend tests 6m1s, frontend tests 2m7s, e2e Playwright 1m39s, all green. The diff shipped as 85 files changed, +12,118 / -32. Almost purely additive, which is what you want from a long-overdue integration merge: it should look like you added a feature, not like you rewrote half the codebase.
I merged with a merge commit, not a squash. The merge commit (b9be7c4) preserves all 174 granular commits as parents. The branch history stays intact and the trunk history stays linear. Both views are correct.
Then the cleanup step that prevents this from recurring:
# Fast-forward the original integration branch to match main.
git checkout siem-loglake
git fetch origin
git reset --hard origin/main
git push --force-with-lease origin siem-loglake
# Close the conflicting PR as superseded.
gh pr close 22 --comment "Superseded by #23 (reconcile branch). Original head retained for history."
siem-loglake is now a strict ancestor of main. The squash-vs-granular divergence cannot recur from this branch because there is no divergence to recur. Any new work starts from a clean base.
The fast-forward step is load-bearing
Without it, the integration branch is still 174 commits "ahead" of main in the sense that it still has those commits as direct descendants, and any new commit on top of it will re-introduce the same conflict shape against the next squash. Reset the integration branch to main right after the reconcile merge lands.
The Playbook in Checklist Form#
Six steps, copy-pasteable:
Squash-vs-granular reconcile playbook
- Throwaway branch.
git checkout -b reconcile/<name> origin/<integration-branch>. Start the merge here so the originals stay clean. - Merge main in.
git merge --no-commit --no-ff origin/main. Stops at conflicts; index has both sides. - Categorize.
git diff --name-only <squash-commit> origin/main-> careful set. Everything else is mechanical. - Resolve mechanically.
while read f; do git checkout --ours -- "$f" && git add -- "$f"; done < group1.txt. - Resolve carefully. Per file:
--theirsfor verified supersets, in-place edits for files with auto-merged regions on both sides,awk-splice for bidirectional additions. - Reproduce trunk cleanup.
make format && make lintas a separate commit. Only after confirming local-vs-CI parity. - Land via PR. Open
reconcile -> mainas a new PR; merge with a merge commit; fast-forward the original integration branch to main; close the old PR as superseded.
The whole thing was about four hours of clock time, most of which was the careful-set hand-merging and the verification. The mechanical step (94 files) took less than a minute. The cleanup commit took ten minutes (most of which was make format actually running).
Related Traps#
This is not the first git ordering trap I have written up on this site. Two earlier ones generalize alongside this one:
Stacked PRs and merge order. GitHub marks a PR as MERGED when its base branch is deleted mid-stack, even if the PR's own content was never integrated anywhere. The defense is to merge stacked PRs bottom-up, and to recover via cherry-pick if you discover one was marked merged without its content landing. The squash-vs-granular trap is the same family of problem at a longer time scale: the trunk got ahead of the integration branch in a way that broke the branch's reachability, and the fix is the same shape (preserve the content, repair the graph, then prevent recurrence).
The companion LOG LAKE panel post. The LOG LAKE dashboard panel was the last big phase of work on siem-loglake before this reconciliation became unavoidable. Phase 6 of the Home Network Mission Control series covers building it (the ingestion strip, the GUI query builder, the persona-team review, the ClickHouse firewall_events field-set corrections). That post ends where this one begins: with a feature ready to ship and a merge that would not happen.
Lessons Learned#
The squash-merge trade-off is the one I keep relearning. Squash keeps the trunk's history clean, but it leaves any long-lived branch still holding the un-squashed version permanently re-conflicting with itself. So squash the short-lived branches that get deleted on merge, and use merge commits for branches that still have people building on them.
Most of the rest comes down to two habits. Categorize before you resolve: with hundreds of conflicts, the actual work is sorting the mechanical ones from the per-file decisions, and getting that 94-vs-11 split right is what made everything after it cheap. And keep in mind that --ours and --theirs are whole-file, so any region git auto-merged from the side you did not pick goes out with the rest of it. For files where both sides contributed, edit the markers by hand.
Two diagnostics earned their keep. If main passes CI but fails make format locally, your local tools have drifted from CI's, and reformatting before you pin them just trades one divergence for another. And if the trunk reformatted files after the squash, that cleanup is its own commit sitting on top of the merge, never folded into it.
The last step is the one that stops the trap from coming back: fast-forward the integration branch to match the trunk once the reconcile lands. One command. Saves a future-you an afternoon.
The mechanical step, 94 files in a while loop, took under a minute. The careful step, 10 files hand-merged with git diff :2:<file> :3:<file> open in another pane, took most of the afternoon. If you keep a long-lived integration branch against a squash-merging trunk, this trap will find you eventually. When it does, the branch merges, the granular history survives as parents of one commit, and the trunk moves on with all the work intact.
Weekly Digest
Get a weekly email with what I learned, summaries of new posts, and direct links. No spam, unsubscribe anytime.

Related Posts
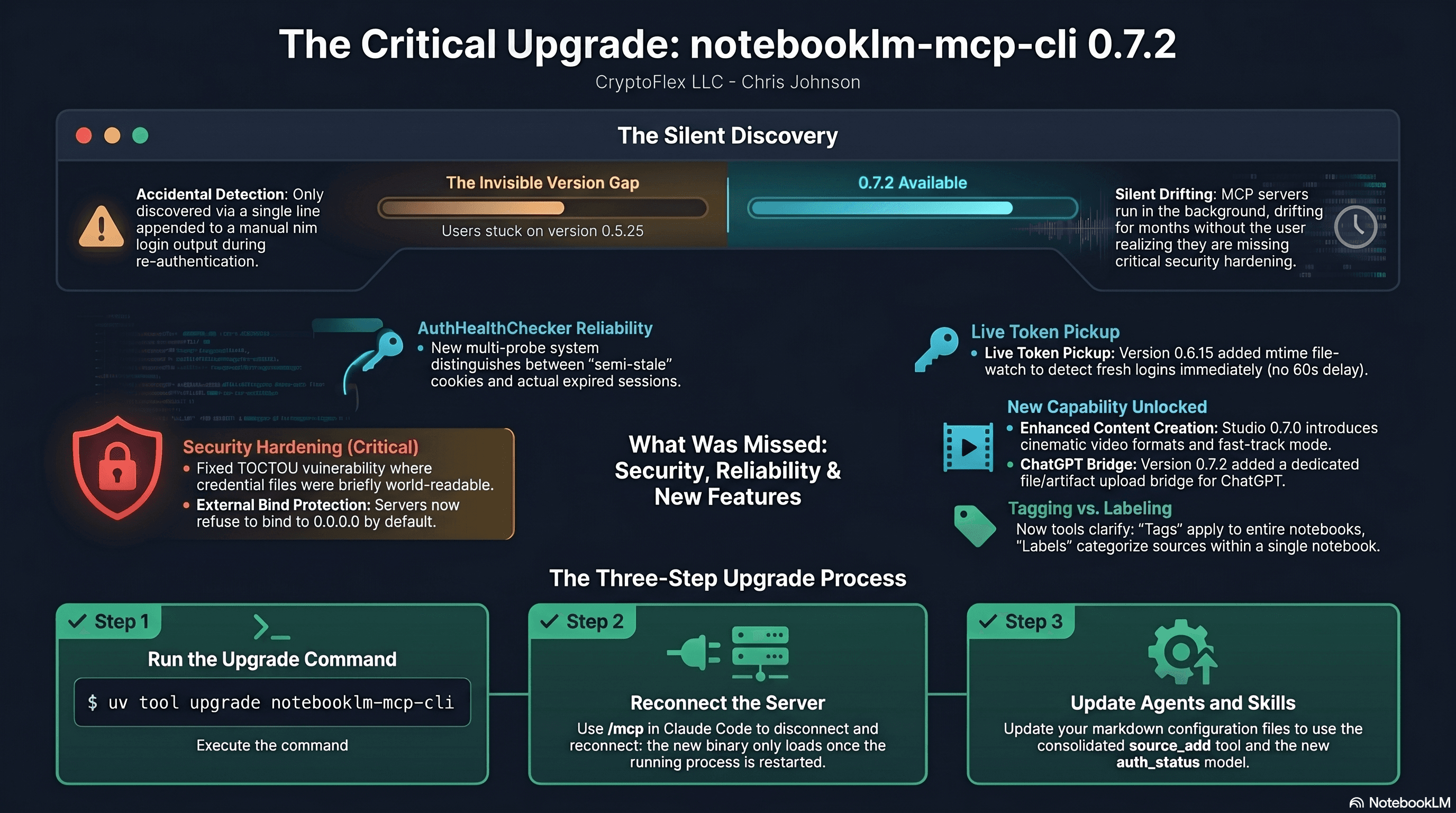
I was two minor versions behind on notebooklm-mcp-cli and had no idea until a re-auth banner interrupted a session. The gap was 0.5.25 to 0.7.2. Security fixes, auth reliability improvements, and new features I was missing the whole time. Here is the three-part upgrade that most people stop after step one.
My Gmail assistant ran clean for two months, then quietly died for a full week before I noticed. The bridge daemon that drove it had pinned itself to a stale Claude CLI version, every scheduled fire failed within seconds, and no transcript was ever written. This post walks through why I migrated the agent off Claude Routines and onto the Claude Agent SDK, what the new stack looks like on launchd, and the parity gate that has to pass before the old agent gets decommissioned.

3 test sessions, 2 MCP servers, 1 wrapper script fix. How I added Exa and Firecrawl to Claude Code for semantic search, JS-rendered scraping, and proper deep research capability.
Comments
Subscribers only — enter your subscriber email to comment