
I Designed 5 Memory Layers. Only 3 Were Actually Running.
I ran a routine audit on my Gmail agent and discovered the knowledge graph had been completely empty for months, the memory nudge hook had five blind spots, and nothing was catching either problem. Here's what I built to fix it.
I ran a routine check on my Gmail assistant agent. Classification accuracy: 55 emails, zero misclassifications. Delta sync: silently failing on every single run. And while I was investigating that, I discovered something worse: the knowledge graph layer of my five-layer memory architecture had been completely empty since the day I designed it.
Not outdated. Not stale. Zero entities. Zero relations. Months of sessions running without structural memory, and nothing had flagged it.
This post is about the weekend I spent finding those gaps and building the feedback loops to make sure they don't happen again. Nothing flashy got built. But the infrastructure that supports my daily development is measurably more reliable now, and the things that were silently failing aren't silent anymore.
Series Context
This is part of an ongoing series on Claude Code workflow. The previous posts covered persistent memory (vector database, two-tier architecture) and smart compact (context preservation before compaction). If those are new concepts, it might help to read them first, though this post stands on its own.
The Session That Started Everything#
The original goal for my session was narrow: audit the Gmail assistant agent, check that its email classification was working, and look at whether delta sync was handling edge cases correctly.
The classification part came back clean. Fifty-five emails processed, zero misclassifications. The categories (newsletter, urgent, social, promotional, and so on) were being applied correctly and the agent's confidence scores looked sensible.
Delta sync was a different story. It was silently failing on every run. No error thrown, no alert sent, no indication anything was wrong. The agent had been running daily, reporting success, and not actually doing the incremental sync work it was supposed to do. That's the kind of failure that's easy to miss precisely because it fails quietly.
But while I was investigating that, I ran a routine check on the broader agent configuration. Which led to a different discovery entirely.
Layer 3 Had Been Empty for Months#
The memory architecture I use has five layers. Here's what they look like and how they relate to each other:
I described this architecture in the persistent memory post. The knowledge graph layer (Layer 3) is handled by the memory MCP server, which stores named entities and the relationships between them. It's designed to answer structural questions: which agents depend on which MCP servers, which hooks govern which tools, what the data flow looks like between services.
When I checked the knowledge graph during the audit, I found zero entities and zero relations.
Not a few outdated entries. Not a stale graph that needed pruning. Completely empty. The infrastructure had been designed, documented, and configured, but no auto-population mechanism existed. Nobody had ever seeded it. Every session that could have been using structural memory had been operating without it.
Designed vs. Actually Working
There's a meaningful difference between "this system is designed" and "this system is operational." The knowledge graph layer had been part of my documented architecture for months. But documentation and actual population are different things. If you haven't checked whether your memory systems are actually being used, check.
Populating the Knowledge Graph#
My first decision was what to put in the graph, and at what granularity. I knew the knowledge graph is best suited for explicit, stable relationships between named components. Not ephemeral working context (that's vector memory's job), and not raw behavioral observations (that's the homunculus layer). The right target is the structural map of my system: what exists, what it does, and how the pieces connect.
I inventoried the components in my CJClaudin_Mac project:
| Category | Count | Examples |
|---|---|---|
| Agents | 20 | gmail-assistant, blog-post-orchestrator, code-reviewer |
| Skills | 8 | smart-compact, Knowledge-Graph-Sync, wrap-up |
| Hooks | 9 | memory-nudge, file-guard, save-session |
| MCP Servers | 11 | vector-memory, memory (KG), github, context7 |
| Rules | 5 | memory-management, coding-style, agentic-workflow |
| Scripts | 12 | sync-status, blog-inventory, session-ingest |
| Commands | 5 | smart-compact, Knowledge-Graph-Sync, skill-catalog |
| Projects | 4 | CJClaudin_Mac, cryptoflexllc, openclaw, claude-code-config |
| Infrastructure | 7 | Mac Mini, Syncthing, launchd, Ollama |
Here's how that breaks down visually:
By the end, the graph had 84 entities and 71 relations. The relations cover orchestration chains (orchestrator invokes agent), invocation paths (hook triggers tool), data flows (agent reads from MCP server), governance (rule governs tool), and replacement history (skill replaced by newer skill).
The result is that structural queries now have answers. "What agents does the blog-post-orchestrator depend on?" resolves immediately. "Which hooks are registered for PostToolUse events?" is a graph query rather than a manual file scan.
Relations Are Where the Value Is
Entities alone are a catalog. Relations are what make a knowledge graph useful. When populating from scratch, focus on the relation types that answer the questions you actually ask: what depends on what, what governs what, what replaced what, what data flows where. An entity list without relations is just documentation you could have written as a table.
Finding the Hook Blind Spots#
With the knowledge graph populated, I turned back to my hook infrastructure. The memory-nudge hook is supposed to remind Claude to save to vector memory when a session has accumulated significant work. In theory, it fires periodically and reinforces the memory-management rule.
In practice, I found five blind spots. Here's what was broken and what I changed:
Blind Spot 1: Markdown Files Were Invisible#
The hook checked whether recent tool calls included writes to files with certain extensions. The extension list covered .ts, .js, .py, .json, .sh, and .yaml. It didn't include .md.
The problem: agents, skills, and commands are all markdown files. When you write a new agent definition at ~/.claude/agents/my-agent.md, or update a skill at ~/.claude/commands/my-skill.md, the hook didn't register any of those writes as work. Entire sessions spent building or refining the agent infrastructure were invisible to the nudge.
Fix: Added .md and .mdx to the extension matcher.
Blind Spot 2: MCP Tool Calls Didn't Count#
The hook's tool matcher only caught Edit|Write|Bash|Agent events. MCP tool calls (mcp__vector-memory__memory_store, mcp__memory__create_entities, and so on) are a distinct event type that wasn't included.
Sessions that were primarily MCP-heavy (populating the knowledge graph, for example) accumulated zero work units from the hook's perspective. A session that ran 40 MCP tool calls would trigger no nudge at all.
Fix: Added mcp__ to the matcher pattern to catch all MCP tool invocations.
Blind Spot 3: Research Sessions Were Silent#
A common session pattern is heavy read-only work: Read, Grep, Glob calls to explore a codebase, understand an architecture, or investigate a bug. These sessions often produce significant findings and decisions that are worth saving to memory.
The original hook only counted write-type events. A three-hour investigation session that ended with five architectural decisions might trigger exactly zero nudge events.
Fix: Added Read|Grep|Glob to the work unit counter. Read-only tool calls count at half weight (0.5 vs 1.0 for write operations) to prevent noisy false positives from routine file reads.
Blind Spot 4: No End-of-Session Check#
The nudge fired at a threshold during the session. It didn't fire at the end of the session. If a session did significant work and then ended before reaching the threshold, no nudge was ever sent.
Fix: Created a separate Stop hook (memory-checkpoint.sh) that fires once when the session ends. More on this below.
Blind Spot 5: The Language Was Too Soft#
The original nudge message said something along the lines of "if you have completed significant work in this session, consider saving to memory."
"If." "Consider." Soft suggestions that Claude's instruction-following would reasonably deprioritize when wrapping up a session.
Fix: Changed the language to "MEMORY SAVE REQUIRED" and replaced the conditional framing with a direct checklist. Same information, much higher compliance rate.
Instruction Strength Matters
When writing instructions for Claude, the framing isn't cosmetic. "If you have completed..." and "You MUST complete the following before finishing" produce different behaviors. For critical operations like memory saving, use direct, imperative language. Soft suggestions get soft compliance.
The Dual-Layer Fix#
The five blind spots pointed me toward a more fundamental issue: a single nudge hook is a single point of failure. If it misses a category of work, that category goes unrecorded. I needed a more robust approach with a second layer.
Here's how the two layers work together:
Layer 1: Patched memory-nudge.sh
The existing hook, fixed. I added .md and .mdx to the extension list, added mcp__ to the tool matcher, added Read|Grep|Glob with half-weight counting, lowered the threshold from 5 to 3 work units, and replaced the soft language with direct imperative framing.
Layer 2: New memory-checkpoint.sh Stop hook
A new hook that fires once per session end (via the Stop event type) and presents a structured five-category checklist:
MEMORY SAVE REQUIRED before finishing this session.
Work from this session that should be saved to vector memory:
[ ] TASKS COMPLETED: Any features, fixes, or changes implemented
[ ] DECISIONS MADE: Architectural or design choices and the reasoning
[ ] BUGS RESOLVED: Root cause, fix applied, how it was discovered
[ ] GOTCHAS FOUND: Anything that took effort to figure out
[ ] ERRORS ENCOUNTERED: Error messages, causes, and solutions
Save any applicable items to vector memory using mcp__vector-memory__memory_store.
Then confirm: "Memory checkpoint complete."
The two layers address different failure modes. The nudge catches sessions that run long and might forget to save mid-session. The checkpoint catches sessions that end before the threshold is reached, or sessions where the nudge fired but was deprioritized.
Neither layer guarantees perfect coverage. But two independent checks are materially better than one, and the structured checklist in the checkpoint provides a consistent format that's easier to act on than a general reminder.
Why Two Layers Instead of One Better Hook
The temptation is to make the single hook smarter until it covers every case. The problem with that approach: a single hook has a single failure mode (if the hook misfires or isn't registered, nothing runs). Two hooks with different trigger conditions (threshold-based vs. session-end) are independently reliable. If one misses something, the other catches it.
Building the KG Maintenance System#
Populating the knowledge graph once is useful. Keeping it accurate over time requires a different kind of solution.
The problem: my knowledge graph reflects the system as it existed when I seeded it. Every time I add a new agent, update a hook, or install a new MCP server, the graph drifts from reality. Without a way to detect and resolve that drift, the graph becomes increasingly stale and increasingly misleading.
I built two tools to address this. Here's the full maintenance loop:
kg-update-detect.sh#
A PostToolUse hook that watches for writes to the tracked component directories: ~/.claude/agents/, ~/.claude/commands/, ~/.claude/hooks/, ~/.claude/skills/, ~/.claude/rules/.
When Claude writes to any of these paths, the hook outputs a reminder:
KG UPDATE NEEDED: You just modified a tracked component directory.
The knowledge graph may be out of sync. Consider running /Knowledge-Graph-Sync
to reconcile, or update the graph manually if the change is small.
This doesn't force an update. It just makes the signal visible at the moment it's most relevant: right after the change that would cause drift.
/Knowledge-Graph-Sync Command#
A five-phase reconciliation skill that can be run on demand:
- Disk inventory: Scan the tracked directories and list every component that currently exists.
- KG inventory: Query the knowledge graph for all entities in the tracked categories.
- Reconcile entities: Compare the two lists. Identify what's in the files but not in the graph (missing), what's in the graph but not in the files (stale), and what exists in both (current).
- Validate relations: For entities that exist in both, check that the relations in the graph still make sense given the current file contents.
- Report: Present a structured summary with add/remove/update recommendations.
The command doesn't automatically mutate the graph. It presents the discrepancies and asks for confirmation before making changes. This is intentional: the knowledge graph contains deliberate relational structure that shouldn't be blindly overwritten by a file scan.
Reconciliation Is Not Sync
The /Knowledge-Graph-Sync command reports drift and recommends changes. It doesn't automatically apply them. Some discrepancies (like a renamed component that still has all its original relations) require human judgment about whether to update the entity name, add an alias, or leave the old entry as historical context. Automation is good for finding problems. Judgment is still required for resolving them.
The Updated Memory Rule#
With all of these pieces in place, my memory-management rule needed an update to document the new responsibilities. The previous rule covered vector memory and the knowledge graph in general terms, but didn't say anything about when the KG should be updated or how to keep it current.
The updated rule adds a "Knowledge Graph Maintenance" section:
## Knowledge Graph Maintenance
The knowledge graph models the structural relationships between system components.
Unlike vector memory (which stores narrative context), the KG stores:
- What components exist (agents, skills, hooks, MCP servers, rules, scripts)
- How they relate (orchestrates, invokes, governs, replaces, reads-from)
**When to update:**
- After adding any new component (agent, skill, hook, command)
- After removing or renaming a component
- After changing how two components relate to each other
**How to update:**
- Small changes: call create_entities/create_relations directly
- Large changes or uncertainty about current state: run /Knowledge-Graph-Sync
The kg-update-detect.sh hook will remind you when relevant changes are detected.
This closes the loop: the rule explains the responsibility, the hook surfaces the signal, and the command provides the reconciliation mechanism.
What This Looks Like in Practice#
A month from now, the maintenance loop should look something like this:
A new agent gets added to ~/.claude/agents/. The kg-update-detect.sh hook fires and outputs a reminder. During or after the session, Claude adds the new entity to the graph and connects it to the MCP servers it uses and the rules that govern it. The graph stays current.
A session spends two hours on agent configuration work. The memory-nudge threshold is reached partway through, reminding Claude to save any completed decisions. At session end, the memory-checkpoint hook fires and walks through the five-category checklist. The work from the session (architectural decisions, gotchas, configuration changes) gets captured in vector memory before the session closes.
Every few weeks, /Knowledge-Graph-Sync gets run to catch any drift that slipped through the per-change detection. The report shows three new entities missing from the graph and one stale entry for a hook that was renamed. Those get reconciled in a few minutes.
None of this is dramatic. It's the maintenance that makes the larger system trustworthy.
Silent Failures Are the Hardest to Find
The Gmail delta sync was silently failing. The knowledge graph was silently empty. The nudge hook was silently missing entire categories of work. None of these failures threw errors. None triggered alerts. They just quietly didn't work. Periodic infrastructure audits find problems that monitoring misses, because monitoring only catches what you knew to look for.
Lessons Learned#
A few patterns from this session that are worth making explicit.
Designed isn't the same as working. The five-layer memory architecture was real and documented. But Layer 3 had been empty since the beginning. Having a plan for a system doesn't mean the system is operational. Operational means running, populated, and verified.
Silent failures compound over time. The delta sync failure, the empty knowledge graph, the hook blind spots: all of them were degrading the system's effectiveness without any obvious signal. The longer these run undetected, the more the gap widens between what you think the system is doing and what it's actually doing.
Two independent checks beat one perfect check. The memory-nudge hook was meant to be sufficient. Making it smarter (adding more extension types, tweaking the threshold) was my first instinct. But a smarter single hook still has a single failure mode. Adding the session-end checkpoint creates redundancy that's architecturally more valuable than additional cleverness in either individual hook.
Hook language is configuration, not just description. The nudge hook's soft language ("consider saving") wasn't a stylistic choice; it was a functional configuration decision that produced softer compliance. Framing is a variable, not a constant.
Maintenance sessions produce value that's hard to see. Nothing new got built this session. But the systems that support ongoing development are more reliable, the memory infrastructure is now actually functioning at all layers, and future sessions will accumulate context more consistently. The value is real; it's just diffuse and delayed.
What Was Built#
For reference, here's the concrete output from the session:
-
Knowledge graph populated: 84 entities, 71 relations covering all 20 agents, 8 skills, 9 hooks, 11 MCP servers, 5 rule sets, 12 scripts, 5 commands, 4 projects, and 7 infrastructure nodes
-
memory-nudge.sh patched: Added
.md/.mdxextensions,mcp__tool prefix,Read|Grep|Globhalf-weight counting, threshold lowered from 5 to 3, language changed to "MEMORY SAVE REQUIRED" -
memory-checkpoint.sh created: New Stop hook with structured five-category end-of-session checklist
-
kg-update-detect.sh created: PostToolUse hook that detects writes to tracked component directories and surfaces a KG update reminder
-
/Knowledge-Graph-Synccommand created: Five-phase disk-to-graph reconciliation skill -
memory-management.md updated: Added Knowledge Graph Maintenance section documenting update responsibilities and tooling
The infrastructure that supports my work is now actually doing what it was designed to do. That's a good day's work, even if none of it is exciting on its own.
Written by Chris Johnson. Part 9 of the Claude Code Workflow series. Previous post: Smart Compact: Never Lose Context When Claude Code Runs Out of Room. The configuration for all hooks, commands, and rules referenced in this post is available in the claude-code-config repo.
Weekly Digest
Get a weekly email with what I learned, summaries of new posts, and direct links. No spam, unsubscribe anytime.

Related Posts
Claude Code's /compact command frees up context but destroys in-progress session state. Smart-compact is a custom skill that saves everything before you compact, so you can pick up exactly where you left off.

How to give Claude Code real persistent memory using a global rule file and a vector database MCP server, so context survives across sessions without any manual effort.
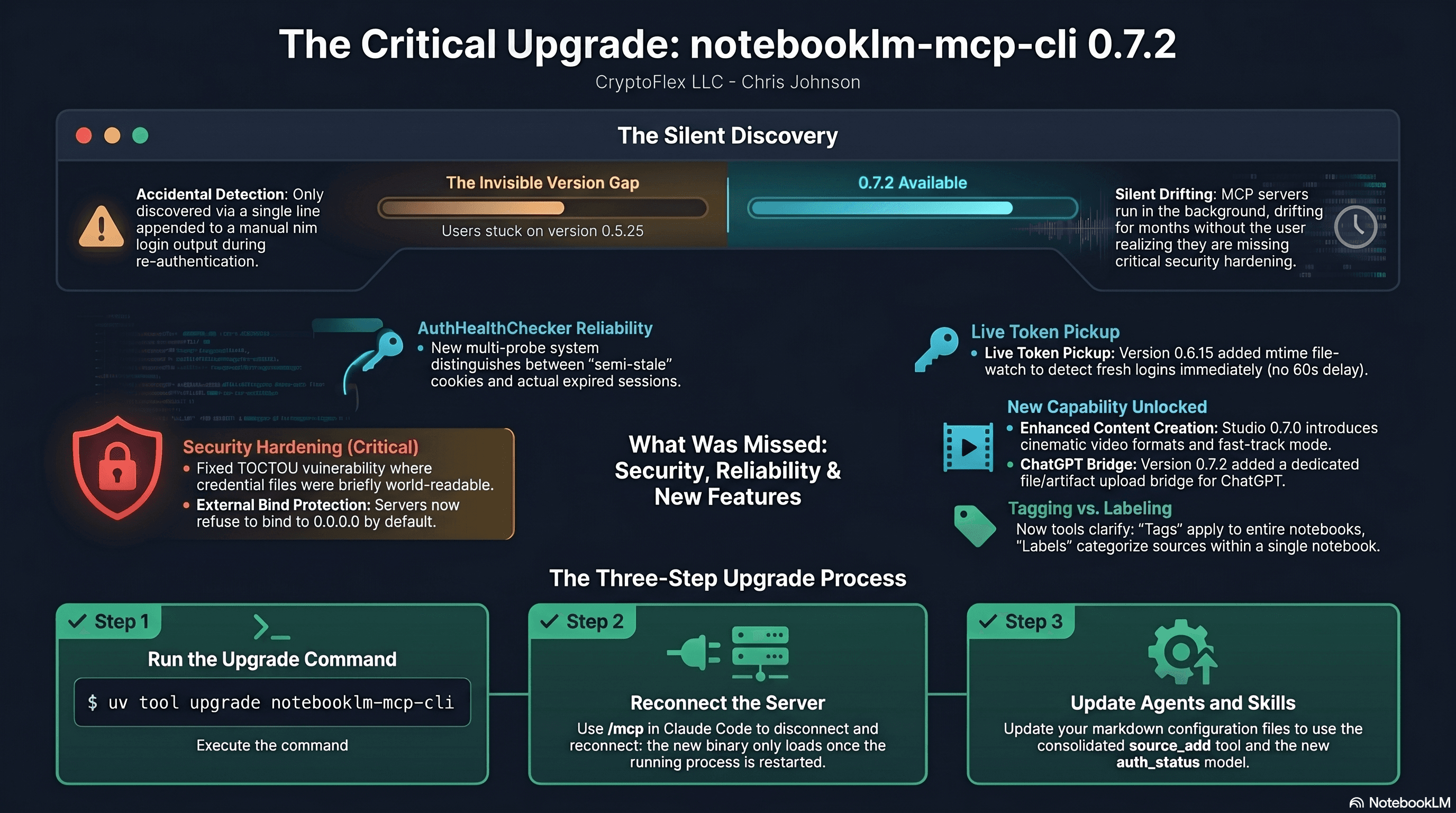
I was two minor versions behind on notebooklm-mcp-cli and had no idea until a re-auth banner interrupted a session. The gap was 0.5.25 to 0.7.2. Security fixes, auth reliability improvements, and new features I was missing the whole time. Here is the three-part upgrade that most people stop after step one.
Comments
Subscribers only — enter your subscriber email to comment