
Will LLM Agents Replace Pentesters? I Ran a 4-Agent Security Sprint to Find Out
I tasked four AI agents with auditing my production site for OWASP vulnerabilities. They found 16 findings, fixed 6, and wrote 37 tests in under 30 minutes. Traditional pentesting may never be the same, but red teamers shouldn't worry.
Four AI agents. Twelve API routes. Sixteen security findings. Thirty minutes.
That's the summary of what happened when I pointed Claude Code's new Agent Teams feature at my production website and said "run an OWASP audit." What came back wasn't a surface-level scan or a list of theoretical vulnerabilities. The agents found real issues: a comment deletion endpoint with no authorization check, subscriber emails leaking in public API responses, and an SSRF bypass that would let an attacker probe my internal network through an IPv6 encoding trick.
Then they fixed them. Wrote the tests. Verified the build.
I'm a security professional. I've done this kind of work manually. What used to take me the better part of a day happened while I watched agent status updates scroll across my terminal. And it forced me to confront a question I've been avoiding: is the pentesting industry, as we know it, on borrowed time?
The Setup: Agent Teams vs. Subagents#
Before diving into the sprint itself, I need to explain what makes Agent Teams different from the subagents that Claude Code has had for a while.
Subagents: Quick, Focused Workers
Subagents (the Task tool) are lightweight. You spawn one, give it a job, it reports back. Think of them as interns: they do exactly what you tell them, they can't talk to each other, and they share the parent session's context limitations. Great for parallelizing simple tasks like "search these three directories" or "run this test suite."
Agent Teams: Independent Collaborators
Agent Teams, shipped with Claude Opus 4.6 on February 5, 2026, are fundamentally different. Each teammate gets its own full context window (up to 200K tokens), its own tool access, and the ability to communicate directly with the team lead and other teammates through a mailbox system. They coordinate through a shared task board where tasks have statuses, dependencies, and ownership. The team lead can create tasks, assign them, and agents can report progress, flag blockers, or create new tasks they discover along the way.
The practical difference matters enormously for security work. A subagent doing an OWASP audit would need me to feed it every file, every route, every piece of context. An Agent Team member can explore the codebase independently, build its own understanding, and surface findings I didn't think to look for.
Here's the cost trade-off: subagents run at roughly 1.5-2x the token cost of doing the work yourself. Agent Teams run at 3-4x because each agent maintains its own full context. For a security audit that would take me hours manually, the extra cost is a rounding error.
The Sprint#
I structured the team as four specialists working in parallel, each with a clear mandate:
┌─────────────────────────────────────────────────────────┐
│ TEAM LEAD (Opus) │
│ Creates tasks, assigns agents, integrates │
├──────────┬──────────┬──────────┬────────────────────────┤
│ │ │ │ │
│ Agent 1 │ Agent 2 │ Agent 3 │ Agent 4 │
│ security │ comment │ rate │ email │
│ auditor │ fixer │ limiter │ retry │
│ │ │ │ │
│ OWASP │ Fix auth │ Add IP │ Exponential │
│ audit │ bypass │ rate │ backoff + │
│ all 12 │ on │ limiting │ subscriber │
│ routes │ DELETE │ to POST │ verification │
│ │ endpoint │ routes │ │
└──────────┴──────────┴──────────┴────────────────────────┘
Each agent had a detailed prompt. The security auditor got instructions to evaluate every route against OWASP Top 10 categories. The other three got specific vulnerabilities I already knew about, plus instructions to write comprehensive tests.
I also set up a task board with dependencies: Task #5 (run the full test suite and verify the production build) was blocked by Tasks #2, #3, and #4. It couldn't start until all three implementation agents finished.
Then I hit enter and watched.
What Happened Next#
Within seconds, all four agents were running simultaneously, each with its own context window, reading files, analyzing code, and writing fixes.
The security auditor finished first. Its report was sobering.
OWASP Audit Results: 16 Findings
| Severity | Count | Key Issues |
|---|---|---|
| CRITICAL | 2 | Email PII exposure, SSRF bypass |
| HIGH | 5 | Rate limiting gaps, phishing vector |
| MEDIUM | 5 | Raw secret in headers, PII logging, input length |
| LOW | 4 | GET mutations, HTTP API, token expiry, email regex |
Two of those CRITICALs weren't covered by any of the three implementation agents. The audit found issues the humans (me) hadn't anticipated. So I created two new tasks on the spot and fixed them myself while the other agents continued working.
Here's what that looked like in the terminal. The team lead (me, via Claude) identified the gap, read the relevant files, and fixed both CRITICALs while three other agents were still writing code in their own context windows:
OWASP audit complete: 16 findings (2 CRITICAL, 5 HIGH, 5 MEDIUM, 4 LOW)
The audit uncovered 2 CRITICAL findings not covered by the current
tasks. Let me address those myself while agents 2-4 work on their tasks.
C1: Remove email PII from public comments response
> Comments GET now returns email_masked (e.g., j***@gmail.com)
C2: isPrivateIp() now normalizes ::ffff: IPv4-mapped IPv6,
plus added fc00::/7 unique local check
The comment-fixer agent finished next with 13 passing tests. Then the rate-limiter with 10 tests. Finally the email-retry agent with 7 tests (and a note about some mock issues it couldn't fully resolve).
The task board tracked it all:
Task Status During Sprint
─────────────────────────────────
#1 OWASP Audit ✓ Done
#2 Comment Auth Fix ✓ Done (13 tests)
#3 Rate Limiting ✓ Done (10 tests)
#4 Email Retry ✓ Done (7 tests)
#5 Test Suite + Build Blocked → #2, #3, #4
#10 Email PII Fix ✓ Done (team lead)
#11 SSRF Fix ✓ Done (team lead)
The Findings: A Technical Walkthrough#
Let me walk through the three most interesting findings, because they illustrate exactly the kind of work that LLMs excel at: pattern recognition across large codebases, awareness of edge cases, and systematic coverage.
Finding 1: Email PII Exposure (CRITICAL)#
The public comments endpoint returned full subscriber email addresses in its JSON response:
-- BEFORE: Anyone visiting the page could see subscriber emails
SELECT id, slug, comment, reaction, email, created_at
FROM blog_comments WHERE slug = $1
This is a public endpoint. No authentication required. Every commenter's email was visible to anyone who opened browser dev tools and looked at the network tab.
Why This Matters
Email addresses are personally identifiable information. Exposing them on a public endpoint violates basic data protection principles and gives attackers a list of verified email addresses for phishing campaigns. The fact that the endpoint "works correctly" doesn't mean it's secure.
The fix: server-side masking at the SQL level.
-- AFTER: Emails masked before they ever leave the database
SELECT id, slug, comment, reaction,
CONCAT(LEFT(email, 1), '***@', SPLIT_PART(email, '@', 2)) AS email,
created_at
FROM blog_comments WHERE slug = $1
Full emails are still stored in the database for admin use. The public endpoint only ever sees j***@gmail.com.
Finding 2: SSRF Bypass via IPv4-Mapped IPv6 (CRITICAL)#
My IP intelligence endpoint already had SSRF protection. It checked incoming IP addresses against private ranges (127.x, 10.x, 192.168.x) before making external API calls. But the security auditor found a bypass:
SSRF Bypass: IPv4-Mapped IPv6 Encoding
───────────────────────────────────────────────
BEFORE (Vulnerable)
┌──────────────────┐ ┌─────────────────┐ ┌──────────────┐
│ Attacker sends: │────▶│ isPrivateIp() │────▶│ External API │
│ ::ffff:127.0.0.1 │ │ checks ^127\. │ │ called with │
│ │ │ NO MATCH ✗ │ │ internal IP! │
└──────────────────┘ └─────────────────┘ └──────────────┘
AFTER (Fixed)
┌──────────────────┐ ┌─────────────────┐ ┌──────────────┐
│ Attacker sends: │────▶│ Normalize: │────▶│ isPrivateIp()│
│ ::ffff:127.0.0.1 │ │ strip ::ffff: │ │ checks ^127\.│
│ │ │ → 127.0.0.1 │ │ MATCH ✓ │
└──────────────────┘ └─────────────────┘ └──────────────┘
│
▼
400: "Private IP
addresses are not
supported"
IPv4-mapped IPv6 addresses (::ffff:127.0.0.1) are a standard way for IPv6 systems to represent IPv4 addresses. They're perfectly legitimate. But if your validation only checks for IPv4 patterns, an attacker can slip an internal address through by wrapping it in the IPv6 format.
The fix is two lines:
const normalized = /^::ffff:/i.test(ip)
? ip.replace(/^::ffff:/i, "")
: ip;
Normalize first, validate second. Also added fc00::/7 (unique local addresses) to the block list, which is the IPv6 equivalent of RFC 1918 private ranges.
Finding 3: Comment Deletion Authorization Bypass (HIGH)#
The DELETE endpoint for comments had no ownership verification:
Comment Deletion Auth Flow
───────────────────────────────────────────────
BEFORE (No Authorization)
┌──────────────┐ ┌──────────────┐
│ Any Request │───────────────────▶│ DELETE FROM │
│ DELETE /5 │ No auth check │ blog_comments │
│ │ │ WHERE id = 5 │
└──────────────┘ └──────────────┘
AFTER (Dual-Path Authorization)
┌──────────────┐ ┌──────────────┐
│ Request │────▶│ Admin auth? │──── Yes ──▶ Delete any comment
│ DELETE /5 │ │ (cookie) │
└──────────────┘ └──────┬───────┘
│ No
▼
┌──────────────┐
│ Email in │──── No ───▶ 403 Forbidden
│ request body?│
└──────┬───────┘
│ Yes
▼
┌──────────────┐
│ Email matches│──── No ───▶ 403 Forbidden
│ comment │
│ owner? │──── Yes ──▶ Delete own comment
└──────────────┘
The comment-fixer agent implemented a dual-path solution: admins (authenticated via cookie) can delete any comment, while subscribers can only delete their own by proving ownership through their email address.
Rate Limiting and Email Resilience#
The other two agents tackled infrastructure hardening:
Rate limiting (Agent 3): Built a sliding-window rate limiter with zero external dependencies. An in-memory Map tracks request timestamps per IP, with automatic cleanup of expired entries.
Sliding Window Rate Limiter
───────────────────────────────────────────────
Time ──────────────────────────────────────▶
Window: [────────── 1 hour ──────────]
IP 203.0.113.1:
Req 1 ─ Req 2 ─ Req 3 ─ Req 4 ─ Req 5 │ Limit: 5/hr
✓ 200 ✓ 200 ✓ 200 ✓ 200 ✓ 200 │
│
Req 6 ────────────────────────────────── │
✗ 429 Too Many Requests │
Retry-After: 2847 │
│
─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─
Window slides: [────────── 1 hour ──────────]
Req 1 expires, new slot opens
Req 7 ──────────────────────────────────
✓ 200 (Req 1 has aged out of window)
Applied to the subscribe endpoint (5 requests/hour per IP) and comments POST (10/hour). No Redis, no database queries, no external dependencies. Just a Map and a timestamp array.
Email retry (Agent 4): Exponential backoff for SMTP operations using the formula baseDelay * 4^attempt (1s, 4s, 16s). Smart enough to skip retries on authentication errors (SMTP code 535, which means the credentials are wrong, and retrying won't help). Also added subscriber existence verification to the weekly digest cron: before sending each email, the system now confirms the recipient is still an active subscriber.
The Test Suite: Where Things Got Interesting#
Here's where the agent team really earned its keep. After all four agents finished their implementation work, I ran the full test suite.
21 failures across 5 files.
Not because the agents wrote bad code. Because their changes interacted with each other in ways that no individual agent could predict. The rate limiter's module-level instance persisted across tests, eventually returning 429s to unrelated test cases. The subscriber verification code added new SQL calls that pre-existing tests didn't account for. The email retry module's fake timers created unhandled promise rejections.
The Integration Problem
This is the fundamental limitation of parallel agents: each works in isolation with its own context window. Agent 1 doesn't know Agent 3 added a rate limiter. Agent 4 doesn't know Agent 2 changed how the mock SQL function gets called. The team lead has to resolve these cross-cutting concerns.
I fixed all 21 failures in three passes. The fixes were mechanical, not creative: adding mock declarations, updating expected status codes, providing additional mockResolvedValueOnce calls for the new SQL queries. The kind of work that requires seeing the whole picture, which is exactly what the team lead's context window is for.
Final result: 457 tests passing across 35 test files. Production build clean. Fifteen files changed, 1,243 lines added.
What AI Can Already Automate#
Let me be direct about what I just watched happen.
Four AI agents performed an OWASP Top 10 audit of a production web application. They identified 16 vulnerabilities across 12 API routes, categorized them by severity, and provided specific remediation guidance with file paths and line numbers. Three additional agents independently wrote secure implementations: input validation, rate limiting, cryptographic improvements, authorization controls. They wrote 37 tests. They verified the production build.
This is not theoretical. This is not "emerging technology." This happened on a Thursday evening while I was taking screenshots.
What Traditional Pentesting Looks Like
A typical web application penetration test follows a well-defined methodology: reconnaissance, scanning, enumeration, exploitation, reporting. The tester runs automated scanners (Burp Suite, OWASP ZAP, Nessus), manually probes endpoints, checks for OWASP Top 10 categories, documents findings, and writes a report. For a small application like mine (12 API routes), this is a one-to-three day engagement billed at $150-300/hour.
The agent team did the assessment phase in under 30 minutes. Not a surface scan. Real findings with real severity ratings and real remediation code. The SSRF bypass via IPv4-mapped IPv6 encoding is the kind of nuanced finding that automated scanners routinely miss because they don't understand the relationship between IPv6 notation and IPv4 validation logic. The agent found it by reading the code, understanding the intent, and identifying the gap.
Industry analysts are already calling it. By 2027, an estimated 99% of vulnerability assessments will be AI-driven, with manual pentesting relegated to a boutique service for niche edge cases. Penetration Testing as a Service (PTaaS) platforms are the fastest-growing segment, combining automated pipelines with human oversight for validation.
The Verizon 2025 Data Breach Investigations Report notes that 82% of exploited vulnerabilities involved human reasoning, exploit chaining, and contextual analysis. But that statistic cuts both ways: it describes the attacks, not the defenses. The defensive assessment (finding the vulnerabilities before attackers do) is exactly the repetitive, systematic, pattern-matching work that LLMs excel at.
The Economics Are Undeniable
My agent team sprint consumed roughly $15-20 in API tokens. A comparable manual pentest would cost $1,500-3,000. Even at 10x the current token cost, AI-driven assessments are an order of magnitude cheaper. And they run at 2 AM on a Sunday if you want them to.
Why Red Teaming Survives#
Here's where my opinion gets strong: pentesting is being automated away, but red teaming isn't going anywhere. And the difference matters enormously.
Pentesting asks: "Can I find technical vulnerabilities in this system?"
Red teaming asks: "Can I compromise this organization?"
Those are fundamentally different questions. One is about technology. The other is about people, processes, and technology together. AI can answer the first question. It cannot answer the second.
ShinyHunters: The Case Study
In June 2025, a threat actor group called ShinyHunters launched a campaign against Salesforce cloud customers. They didn't scan for CVEs. They didn't exploit a zero-day. They picked up the phone.
ShinyHunters operatives impersonated IT support staff and used voice phishing (vishing) to trick employees into installing a malicious version of Salesforce's Data Loader tool. Through compromised OAuth tokens, they claimed to have stolen over 1.5 billion Salesforce records from 760 companies. Confirmed breaches included Google, Cisco, Adidas, Qantas, and Allianz Life.
By November 2025, they'd hit Mixpanel (affecting Pornhub and OpenAI). By December, SoundCloud (29.8 million accounts). By January 2026, Panera Bread (5 million people).
ShinyHunters doesn't write exploits. They recruit operators based on "proven social engineering skills via phone calls." Some members previously ran cryptocurrency scams impersonating Coinbase and Apple support staff. Their technical sophistication is secondary to their human engineering: they study organizations, identify targets, build rapport over the phone, and convince employees to hand over credentials.
No LLM is going to do that. Not because the technology isn't good enough, but because effective social engineering requires reading emotional cues in real-time voice conversations, adapting to unexpected responses, building trust through cultural fluency, and making judgment calls about when to push and when to back off. It requires being human.
And that's just the phone calls. Red team operations include physical security assessments (tailgating into buildings, cloning RFID badges at coffee shops, planting USB drops), supply chain analysis, insider threat simulation, and the kind of creative lateral thinking that comes from understanding how organizations actually work, not just how their code is structured.
Red Teaming Tests the Whole System
A penetration test tells you that your isPrivateIp() function doesn't handle IPv6 notation. A red team operation tells you that your receptionist will hold the door for someone carrying a box of donuts, your help desk will reset a password over the phone if the caller knows the employee's manager's name, and your VPN credentials are for sale on a Telegram channel because an employee reused their corporate password on a breached gaming forum. These are different categories of risk entirely.
ShinyHunters later merged with Scattered Spider and LAPSUS$ into a declared alliance called "Scattered LAPSUS$ Hunters," combining social engineering expertise with identity compromise and living-off-the-land techniques. This isn't script kiddies running automated tools. This is organized adversary tradecraft that adapts faster than any automated system can model.
The Uncomfortable Truth for Pentesters#
I'm going to say what the industry reports are tiptoeing around: traditional penetration testing, the kind where a consultant runs Burp Suite against your web app for three days and writes a PDF, is being automated out of existence.
Not tomorrow. Not completely. But the trajectory is unmistakable.
The Industry Forecast
Multiple analyst firms predict that by 2027, manual pentesting will be a boutique service for niche problems while the vast majority of vulnerability assessments will be agentic. PTaaS platforms (Rapid7, Secureworks, NetSPI) are already shifting their models to combine automated pipelines with human validation as a premium tier.
The work that survives is the work that requires judgment, creativity, and adversarial thinking:
-
Threat modeling: Understanding which assets matter and which attack paths are realistic for your specific threat landscape. An AI can scan every endpoint, but it can't tell you that your real risk is a disgruntled contractor with VPN access.
-
Business logic testing: Finding flaws in how the application implements business rules. An AI can find SQL injection. It's much harder for it to understand that a discount code stacking vulnerability lets attackers get products for free.
-
Red team operations: Social engineering, physical security, and adversary emulation. The human element isn't a limitation of current AI. It's the entire point.
-
AI validation: Ironically, one of the fastest-growing roles in security will be validating AI-generated findings. My agent team produced 16 findings, but I still needed to review each one for accuracy, assess real-world impact, and prioritize remediation. The human isn't running the scan anymore. The human is curating the results.
If You're a Pentester, Here's My Advice
Pivot toward the work machines can't do. Learn social engineering. Get comfortable with physical security assessments. Develop expertise in threat modeling and business logic analysis. Or become the person who validates and curates AI-generated security findings, because someone has to be accountable for the results, and that someone needs to understand both the technology and the business context.
What I Learned#
This sprint changed how I think about security testing. Not because the technology is perfect (it isn't: 21 test failures, a frontend-breaking column alias I didn't catch until after the commit, and 10 audit findings still unaddressed). But because the feedback loop is so compressed.
The old cycle: plan the engagement, schedule the pentest, wait for the report, triage findings, schedule remediation, verify fixes. Weeks to months.
The new cycle: describe the threat model, spawn agents, review findings, fix issues, verify tests. One session.
Agent Teams: When to Use Them
Use subagents for quick, independent tasks that report back (file search, test running, simple code generation). Use agent teams when the work requires exploration, inter-agent coordination, and the ability to surface unexpected findings. Security audits, large refactoring efforts, and multi-component feature builds are ideal candidates.
The 457 passing tests and clean production build at the end aren't just a quality metric. They're evidence that AI-driven security work can produce verifiable, deployable results, not just reports that sit in a PDF.
Pentesting as a commodity service is on its way out. The value was never in running the scanner. It was in understanding the results. And as AI gets better at both, the human role shifts from "find the vulnerabilities" to "understand the risk and make decisions about it."
Red teamers, on the other hand, can sleep soundly. No AI is going to impersonate your IT department, convince your receptionist to let them into the server room, and walk out with a disk image. That's human work. That's always going to be human work.
And honestly? That's a good thing. The boring, repetitive parts of security testing get automated. The creative, adversarial, deeply human parts stay with us. That's not the end of security. It's the beginning of better security.
Written by Chris Johnson and edited by Claude Code (Opus 4.6) and Claude Code Agent Teams. The full source code is at github.com/chris2ao/cryptoflexllc. This post is part of a series about AI-assisted development. Previous: AI-Powered Newsletter Intros with Claude Haiku. Next: Mine Over Matter.
Weekly Digest
Get a weekly email with what I learned, summaries of new posts, and direct links. No spam, unsubscribe anytime.

Related Posts
What happens when a 5-agent security team audits a client-side browser game? 26 findings, a 'God Mode in 30 seconds' attack chain, and 4 parallel developers shipping every fix before the coffee got cold.
A 5-agent team chewed through a week of Claude Code session logs and surfaced patterns I never would have found manually. Including the revelation that my worst day wasn't actually that bad.
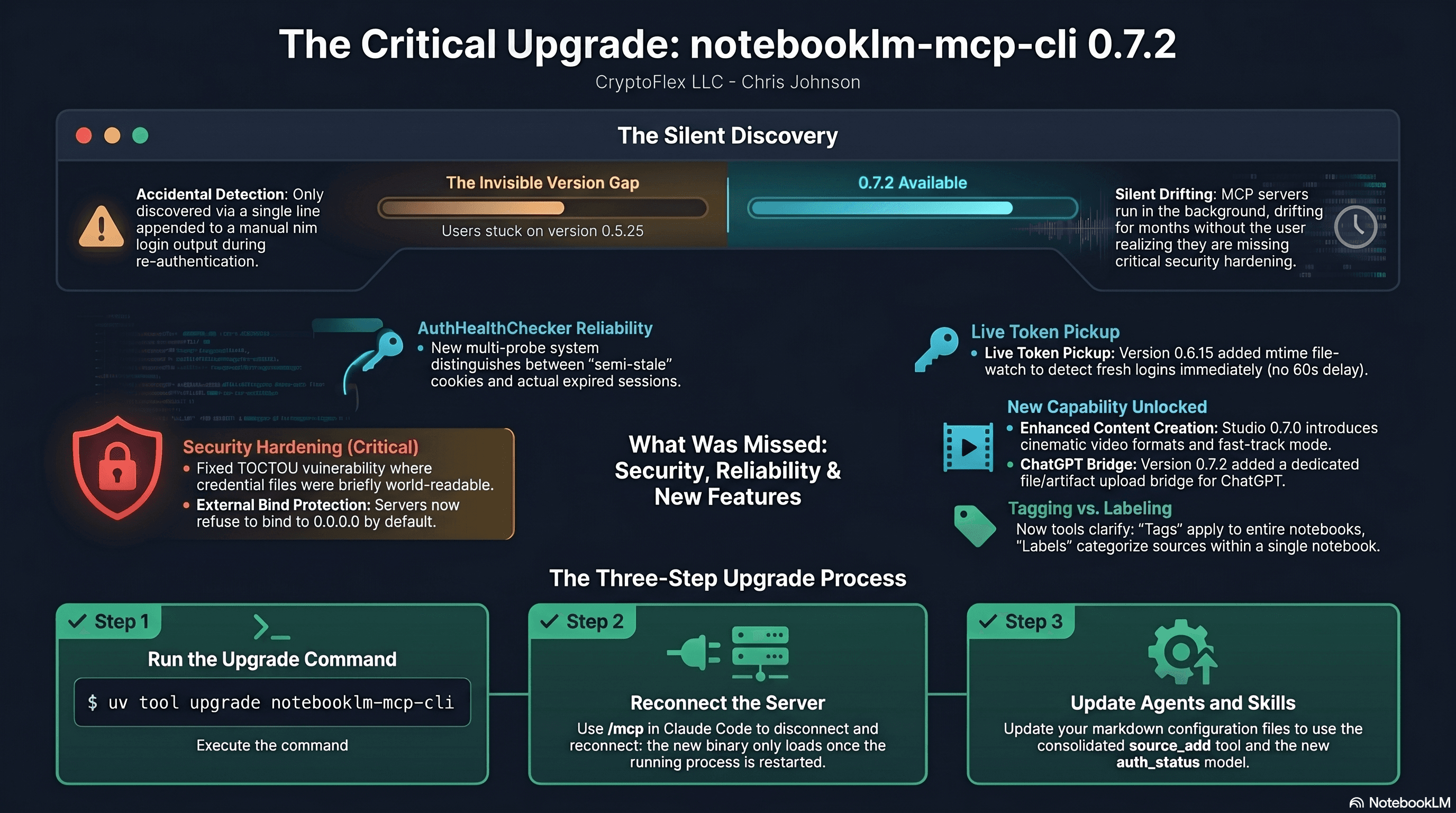
I was two minor versions behind on notebooklm-mcp-cli and had no idea until a re-auth banner interrupted a session. The gap was 0.5.25 to 0.7.2. Security fixes, auth reliability improvements, and new features I was missing the whole time. Here is the three-part upgrade that most people stop after step one.
Comments
Subscribers only — enter your subscriber email to comment