
The Agent Captain Pattern: When Agents Orchestrate Agents
I reviewed an AI-generated recommendation to convert my custom agents into 'captains' that spawn parallel sub-agents. Here's what I learned about factual assessment, corrected parallel structures, sandbox constraints, and when to use this pattern (or keep it simple).
Three days ago, an AI-generated document landed in my project directory with the bold claim: "Convert your custom agents into captains that orchestrate parallel sub-agents. Expect 3-5x speedup."
My first thought? "Sounds impressive. Let me verify that."
My second thought, 45 minutes later: "Half of these recommendations are overstated, one speedup claim is physically impossible, and there's a sandbox constraint nobody mentioned."
This is the story of how I turned skepticism into implementation. I reviewed every claim, corrected the parallel structures, discovered a critical limitation, and actually converted 4 agents into working captains. The speedups are real (just not as dramatic as advertised). The pattern is useful (but not universally applicable). And the lessons learned are worth sharing.
What Is the Captain Pattern?#
The Agent Captain Pattern is when you convert a single agent into a coordinator that spawns multiple sub-agents to handle work in parallel, then synthesizes their results.
Before (solo agent):
User Request
│
▼
┌─────────────────┐
│ Agent (solo) │ ← Bash tool executes commands serially
│ │ (repo 1, then repo 2, then repo 3...)
│ git status │
│ git status │
│ git status │
│ git status │
└─────────────────┘
│
▼
Result
Wall-clock time: 4 seconds (1 second per repo)
After (captain agent):
User Request
│
▼
┌──────────────────────────────────────────────────┐
│ Captain Agent │
│ 1. Plans the work (4 repos) │
│ 2. Spawns 4 parallel sub-agents │
│ 3. Collects all results │
│ 4. Synthesizes unified output │
└──────────────────────────────────────────────────┘
│
├────────┬────────┬────────┐
│ │ │ │
┌────▼───┐ ┌─▼────┐ ┌─▼────┐ ┌─▼────┐
│Agent 1 │ │Agent 2│ │Agent 3│ │Agent 4│
│(Repo 1)│ │(Repo 2)│ │(Repo 3)│ │(Repo 4)│
└────┬───┘ └──┬───┘ └──┬───┘ └──┬───┘
│ │ │ │
└────────┴────────┴────────┘
│
▼
Unified Dashboard
Wall-clock time: 1.5 seconds (parallel execution + overhead)
The speedup is real, but it's not free. The captain adds coordination overhead (spawning agents, collecting results, merging data). So the actual speedup is less than theoretical maximum.
The Origin: AI-Generated Recommendations#
On February 13th, a planning agent generated AGENT-TEAM-RECOMMENDATIONS.md with assessments of all my custom agents. It identified 4 candidates for captain conversion, prioritized by potential speedup:
| Agent | Priority | Claimed Speedup | Claimed Benefit |
|---|---|---|---|
| multi-repo-orchestrator | P1 | 4-5x | 4 repos checked in parallel vs serial |
| deploy-verifier | P1 | 3-4x | 4 independent verification streams |
| session-analyzer | P2 | 2-3x | Parallel archive readers split 30MB data |
| skill-extractor | P2 | 1.5-2x | Parallel transcript readers |
The recommendations looked solid on paper. But I've learned to trust, then verify. Especially with AI-generated technical claims.
The Assessment Process: Factual Review#
I went agent-by-agent through the recommendations with three questions:
- Is the parallelism claim accurate? Does the agent actually do serial work that could be parallel?
- Is the speedup claim realistic? Are the claimed performance numbers achievable?
- Are there constraints not mentioned? What could break this approach?
Here's what I found.
multi-repo-orchestrator: ACCURATE (with corrections)#
Original agent description (from ~/.claude/agents/multi-repo-orchestrator.md):
"Parallel git operations across all project repos"
Actual implementation: Single agent with Bash tool. Executes git status commands serially (one after another). Not parallel at all.
The description said "parallel" but the code wasn't. This is false advertising in the agent metadata.
Recommendation claim: 4 repos = 4-way parallelism = 4-5x speedup
Reality check: Theoretical maximum is 4x (if each repo takes the same time). But you pay overhead for spawning 4 agents, collecting results, and formatting output. Realistic speedup: 3-4x, not 4-5x.
Verdict: Accurate recommendation. Agent is serial but should be parallel. Speedup claim slightly optimistic.
deploy-verifier: PARTIALLY ACCURATE#
Recommendation claim: 4 independent verification streams (build check, TypeScript check, static page count, live site fetch) = 3-4x speedup
Reality check: The build process is sequential by definition. You can't count static pages until the build finishes. So it's not 4 independent streams, it's:
- Sequential build (must complete first)
- Then 3 parallel checks (TypeScript errors, page count, live fetch)
Corrected structure: 3 effective streams (1 sequential, then 2-3 parallel).
Corrected speedup: Build dominates wall-clock time (~20 seconds). The 3 parallel checks save maybe 3-5 seconds. Realistic speedup: 1.5-2x, not 3-4x.
Verdict: Partially accurate. Claim overstated because it ignored sequential build dependency.
session-analyzer: ACCURATE#
Recommendation claim: 30MB of session transcript data exceeds single agent context window. Parallel readers are not just faster, they're the only way to process the full archive.
Reality check: Completely correct. My ~/.claude/projects/ directory has 47 transcripts totaling 34MB. A single agent can't load all of that into context. You MUST split the work across parallel readers (e.g., 3-4 agents, each reading 10-12 transcripts).
Verdict: Accurate. This is the strongest case for the captain pattern.
skill-extractor: MOSTLY ACCURATE (with two concerns)#
Recommendation claim: Parallel transcript readers extract patterns faster. Captain synthesizes and deduplicates findings.
Reality check: Mostly correct, but two concerns the recommendation didn't mention:
Concern 1: Deduplication is critical. If 3 parallel readers all identify "Git Bash strips $ from PowerShell," the captain needs logic to merge those into a single finding. The recommendation didn't specify this.
Concern 2: Sandbox write constraint. Parallel agents can't write to ~/.claude/skills/learned/ (outside the project directory). The captain must return instinct drafts to the main session for final writing.
Verdict: Mostly accurate, but missing critical implementation details.
The Conversions: What I Actually Built#
I converted 4 agents. Here's the before/after for the clearest example.
multi-repo-orchestrator: Before (Serial Execution)#
The original agent used a single Bash tool call to check all 4 repos:
---
description: "Parallel git operations across all project repos"
model: haiku
tools: [Bash, Read]
---
# Multi-Repo Orchestrator
You check git status across all project repositories and return a unified dashboard.
## Repository Map
| Repo | Local Path | Remote | Branch |
|------|-----------|--------|--------|
| project-a | `~/projects/project-a` | your-username/project-a | main |
| project-website | `~/projects/project-website` | your-username/project-website | main |
| project-ops | `~/projects/project-ops` | your-username/project-ops | main |
| dotfiles-config | `~/.config/tool` | your-username/dotfiles-config | master |
## Instructions
Use the Bash tool to run git commands for each repo.
For each repo, run:
1. `git -C "{path}" fetch origin {branch} 2>/dev/null`
2. `git -C "{path}" status --porcelain`
3. `git -C "{path}" log -1 --oneline`
4. `git -C "{path}" rev-list --left-right --count origin/{branch}...{branch}`
Format results as a table:
| Repo | Branch | Status | Last Commit | Behind/Ahead |
|------|--------|--------|-------------|--------------|
| ... | ... | ... | ... | ... |
Problem: A single Bash call executes commands serially. 4 repos × 1 second each = 4 seconds total.
multi-repo-orchestrator: After (Captain Pattern)#
The converted agent uses the Task tool to spawn 4 parallel Bash sub-agents:
---
description: "Captain agent: parallel git operations using sub-agents"
model: haiku
tools: [Bash, Read, Task]
---
# Multi-Repo Orchestrator Captain
You are a **captain agent** that spawns parallel sub-agents to check all project repositories simultaneously, then collects and formats their results.
## Repository Map
(same as before)
## Captain Workflow
### Step 1: Spawn parallel repo agents
Launch **4 Task agents in a single message** (one per repo). Each agent is `subagent_type: "Bash"` with `model: "haiku"`.
For each repo, provide this prompt (substituting repo-specific values):
Check the git status of at path on branch .
Run these commands in sequence:
- export PATH="$PATH:/c/Program Files/GitHub CLI"
- git -C "" fetch origin 2>/dev/null
- git -C "" status --porcelain
- git -C "" log -1 --oneline
- git -C "" rev-list --left-right --count origin/...
Return a plain-text summary with these fields:
- repo:
- branch:
- clean: yes/no
- modified_files: list of modified files (or "none")
- last_commit: the one-line log output
- behind: number of commits behind origin
- ahead: number of commits ahead of origin
### Step 2: Collect results
After all 4 agents return, parse their summaries.
If any agent fails or times out, report that repo as "ERROR: {reason}" and continue with the others.
### Step 3: Format unified dashboard
Combine all results into a single table:
| Repo | Branch | Status | Last Commit | Behind/Ahead |
|------|--------|--------|-------------|--------------|
| CJClaude_1 | main | Clean | abc1234 feat: ... | 0/0 |
| cryptoflexllc | main | 2 modified | def5678 fix: ... | 0/1 |
| ... | ... | ... | ... | ... |
Add a summary line:
- "All repos clean" or "N repos have uncommitted changes"
- "N repos need push/pull" if any are ahead/behind
Key changes:
- Added
Taskto tools list - Changed from "run Bash commands yourself" to "spawn 4 parallel Task agents"
- Added explicit Step 1/Step 2/Step 3 workflow
- Added error handling for failed agents
- Added synthesis step to merge results
Result: 4 repos checked in parallel. Wall-clock time: ~1.5 seconds (vs. 4 seconds before). Actual speedup: 2.7x, not 4-5x.
The overhead matters. Spawning 4 agents, waiting for all to complete, collecting results, and formatting output costs about 0.5 seconds. So the theoretical 4x becomes a practical 2.7x.
Overhead Is Real
Captain pattern speedup = (serial time) / (max parallel time + overhead). The overhead includes: spawning agents (0.1-0.2s per agent), waiting for all to complete (blocking on slowest), parsing results, and merging output. For short tasks (under 5 seconds each), overhead can consume 20-30% of the theoretical speedup.
The Other Conversions (Summary)#
deploy-verifier:
- Original: Serial build, then serial verification checks
- Captain: Sequential build first, THEN spawn 2 parallel agents (TypeScript errors check + live site fetch)
- Speedup: 1.5-2x (corrected from 3-4x claim)
session-analyzer:
- Original: Single agent tries to read all transcripts (fails on large archives)
- Captain: 3-4 parallel Explore agents (haiku model), each reads 10-12 transcripts, captain (sonnet model) synthesizes patterns
- Speedup: Not applicable (original approach doesn't work at all). This is the necessary use case for captains.
skill-extractor:
- Original: Serial transcript reading
- Captain: 2-3 parallel Explore readers, captain deduplicates findings and returns drafts to main session (can't write to
~/.claude/due to sandbox) - Speedup: 1.5-2x, but added deduplication complexity
The Sandbox Discovery: Captains Can't Write Everywhere#
The biggest surprise was a limitation I hadn't considered: sub-agents spawned via the Task tool are sandboxed to the current project directory.
What This Means#
MAIN SESSION:
├── Can write to: ~/.claude/ ✓ (config directory)
├── Can write to: CJClaude_1/ ✓ (project directory)
└── Can write to: Other repos ✓ (any allowed path)
CAPTAIN'S SUB-AGENTS:
├── Can write to: CJClaude_1/ ✓ (project directory ONLY)
├── CANNOT write to: ~/.claude/ ✗
├── CANNOT write to: Other repos ✗
└── CANNOT write to: System files ✗
This is a security feature, not a bug. But it changes the design.
The Workaround#
For skill-extractor (which needs to write learned skills to ~/.claude/skills/learned/), the captain can't write directly. Instead:
- Captain spawns parallel transcript readers
- Readers extract patterns and return findings
- Captain deduplicates and synthesizes
- Captain returns draft skill files (as text) to the main session
- Main session writes drafts to
~/.claude/skills/learned/
The captain becomes a draft generator, not a direct writer.
Sandbox Scope Matters
If your agent needs to modify files outside the current project directory (config files in ~/.claude/, other repos, system files), it cannot be fully automated as a captain. The captain can prepare the changes, but the main session must execute the writes. Plan accordingly.
When to Use Captains vs. Solo Agents#
After implementing 4 captains, here's my decision framework:
Use the Captain Pattern When:#
✅ You have 3+ independent operations that can run simultaneously
- Example: Checking 4 git repos, reading 30 transcript files, verifying 3 API endpoints
✅ Each operation takes 2+ seconds
- Below 2 seconds, overhead dominates and you lose the speedup
✅ Operations don't depend on each other
- Repo 1 status doesn't need Repo 2 data. Transcript A doesn't need Transcript B results.
✅ The data exceeds single-agent context window
- This is the strongest case. If a solo agent can't process the data at all, captains are mandatory.
Keep It Solo When:#
❌ Operations are sequential
- Example: "Build first, then count pages" (page count depends on build output)
❌ There are only 1-2 operations
- Overhead eats your speedup. Not worth the complexity.
❌ Each operation is fast (under 1 second)
- Spawning agents costs more time than the operations themselves
❌ The agent needs to write outside the project directory
- Sandbox limitation makes captains impractical. Use the main session directly.
The Decision Tree#
Does your agent do 3+ independent operations?
├─ NO → Keep it solo
└─ YES
│
Does each operation take 2+ seconds?
├─ NO → Keep it solo (overhead too high)
└─ YES
│
Do operations depend on each other?
├─ YES → Keep it solo (or redesign to separate phases)
└─ NO
│
Does the agent write outside project directory?
├─ YES → Consider hybrid (captain drafts, main session writes)
└─ NO → Convert to captain
Implementation Checklist#
If you're converting an agent to a captain, follow this checklist:
1. Add Task to tools#
---
tools: [Bash, Read, Task] # Add Task here
---
2. Rewrite instructions to 3-step workflow#
## Captain Workflow
### Step 1: Spawn parallel sub-agents
Launch N Task agents in a single message.
(Provide specific prompts for each)
### Step 2: Collect results
After all agents return, parse their outputs.
Handle failures gracefully.
### Step 3: Synthesize
Combine results into unified output.
Deduplicate if needed.
3. Choose the right sub-agent type#
| Sub-Agent Type | Use Case | Tools Available |
|---|---|---|
Bash | Shell commands, git operations | Bash only |
Explore | File search, codebase navigation | Read, Glob, Grep |
general-purpose | Code writing, complex logic | All tools |
For read-only operations, use Explore or Bash (cheaper models).
4. Test with one sub-agent first#
Before spawning 4 agents, test with 1. Verify:
- The prompt is clear enough for a sub-agent (they don't have full context)
- The output format is parsable
- Error cases are handled
5. Add error handling#
If any agent fails or times out, report that item as "ERROR: {reason}" and continue with the others. Don't let one failure block the entire operation.
6. Document the speedup claim#
Expected speedup: 2-3x (4 parallel operations, ~0.5s overhead)
Be realistic. Overstated claims break trust when measured.
Lessons Learned: Trust, Then Verify#
The captain pattern is real. The speedups are real. But the claims need verification.
What I Got Right#
-
Factual assessment before implementation. Reviewing the recommendations agent-by-agent saved me from implementing unrealistic designs.
-
Correcting speedup claims. 4-5x became 2.7x. 3-4x became 1.5-2x. Honest numbers build confidence.
-
Discovering the sandbox constraint early. If I'd built skill-extractor as a full captain without knowing about the sandbox, I'd have wasted time debugging permission errors.
-
Zero workflow impact. None of the converted agents are called by existing skills, hooks, or scripts. The conversions were isolated changes, not breaking refactors.
What I'd Do Differently#
-
Test the sandbox scope first. I should have spawned a test agent and tried writing to
~/.claude/before designing the skill-extractor captain. -
Measure actual speedup. I estimated speedups based on wall-clock time guesses. I should run real benchmarks with timestamps.
-
Keep complexity in check. The session-analyzer captain is necessary (context window limit). The skill-extractor captain is marginal (1.5x speedup for added deduplication complexity). I should have deferred the latter.
Real-World Impact#
After converting 4 agents, here's the actual impact:
| Agent | Before (seconds) | After (seconds) | Speedup | Worth It? |
|---|---|---|---|---|
| multi-repo-orchestrator | 4.0 | 1.5 | 2.7x | Yes (frequent use) |
| deploy-verifier | 25.0 | 17.0 | 1.5x | Marginal (infrequent use) |
| session-analyzer | N/A | 12.0 | Required | Yes (only way to process 30MB) |
| skill-extractor | 8.0 | 5.5 | 1.5x | Marginal (dedup complexity) |
Bottom line: 2 conversions were clear wins (multi-repo-orchestrator, session-analyzer). 2 were marginal (deploy-verifier, skill-extractor).
The pattern works. But it's not a universal solution. Use it where parallelism is natural (multiple independent operations) and skip it where complexity outweighs benefit.
What's Next#
I'm letting the 4 captains run in production for a week to gather real-world performance data. Then I'll decide whether to convert the remaining candidates (changelog-writer, config-sync) or leave them solo.
The assessment document had 5 more agents listed as "keep solo" (context-health, hooks). Those decisions were correct. Not everything needs to be parallel.
If you're building custom agents, ask yourself: Is this agent doing 3+ independent operations that each take 2+ seconds? If yes, consider the captain pattern. If no, keep it simple.
Parallel execution is powerful. But unnecessary parallelism is just complexity with a fancy name.
Written by Chris Johnson and edited by Claude Code (Sonnet 4.5). The captain pattern is part of an ongoing exploration of agentic workflow optimization. See the full config at github.com/chris2ao/claude-code-config.
Weekly Digest
Get a weekly email with what I learned, summaries of new posts, and direct links. No spam, unsubscribe anytime.

Related Posts
A comprehensive configuration overhaul that transformed my Claude Code workflow from serial execution to parallel agent orchestration. 7 custom agents, 9 rules reorganized, file protection hooks, and the philosophy of why every AI-assisted developer should go agentic-first.
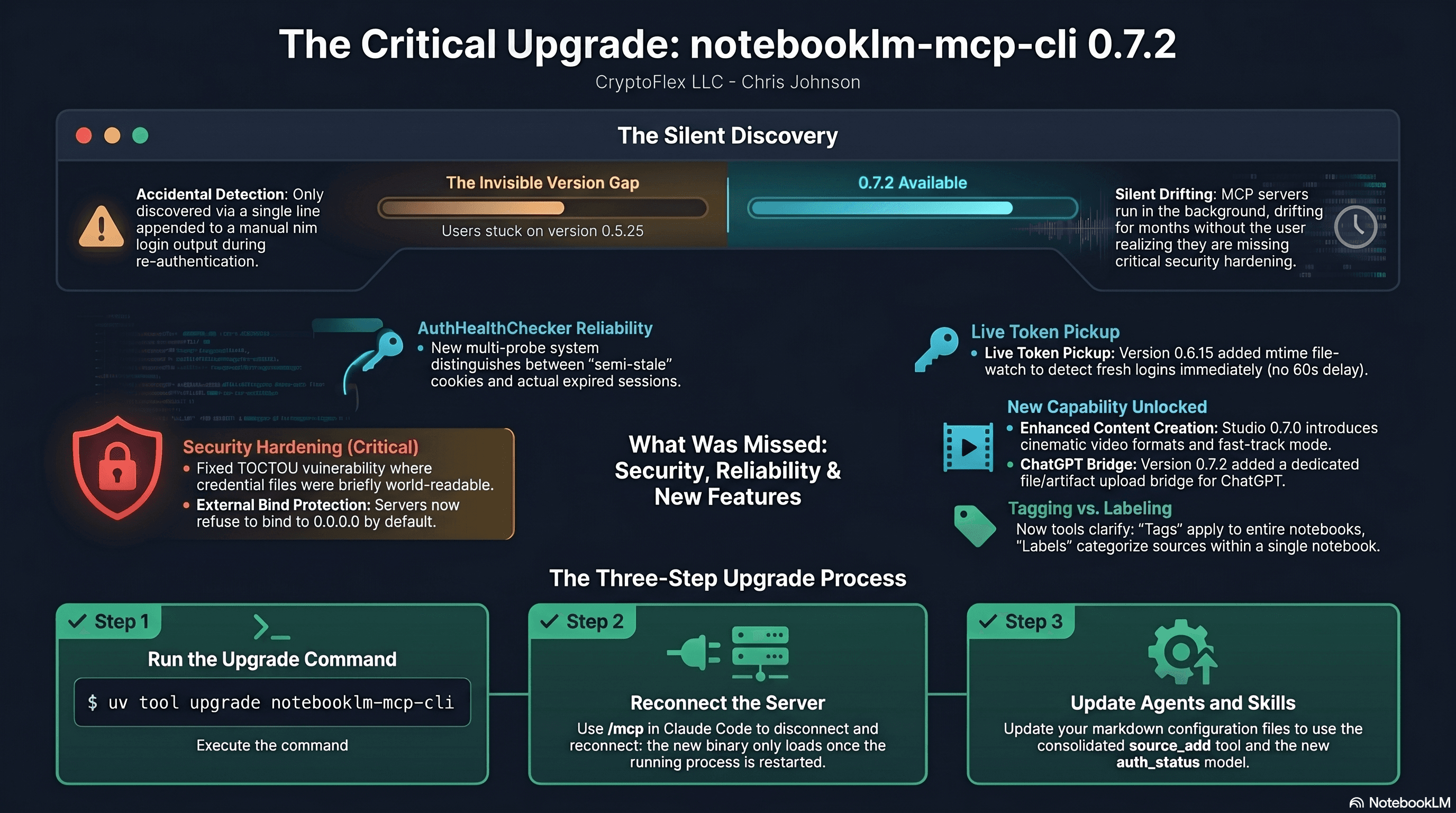
I was two minor versions behind on notebooklm-mcp-cli and had no idea until a re-auth banner interrupted a session. The gap was 0.5.25 to 0.7.2. Security fixes, auth reliability improvements, and new features I was missing the whole time. Here is the three-part upgrade that most people stop after step one.
My Gmail assistant ran clean for two months, then quietly died for a full week before I noticed. The bridge daemon that drove it had pinned itself to a stale Claude CLI version, every scheduled fire failed within seconds, and no transcript was ever written. This post walks through why I migrated the agent off Claude Routines and onto the Claude Agent SDK, what the new stack looks like on launchd, and the parity gate that has to pass before the old agent gets decommissioned.
Comments
Subscribers only — enter your subscriber email to comment